LSTM: Music generation
We will implement a model that uses an LSTM (long short-term memory) to generate music. We will train a network to generate novel jazz solos in a style representative of a body of performed work.

I did this project in the Sequence Models course as part of the Deep Learning Specialization.
Dataset
We have 60 training examples, each of which is a snippet of 30 musical values. At each time step (of the total 30 steps), the input is one of 90 different possible musical values, represented as a one-hot vector.
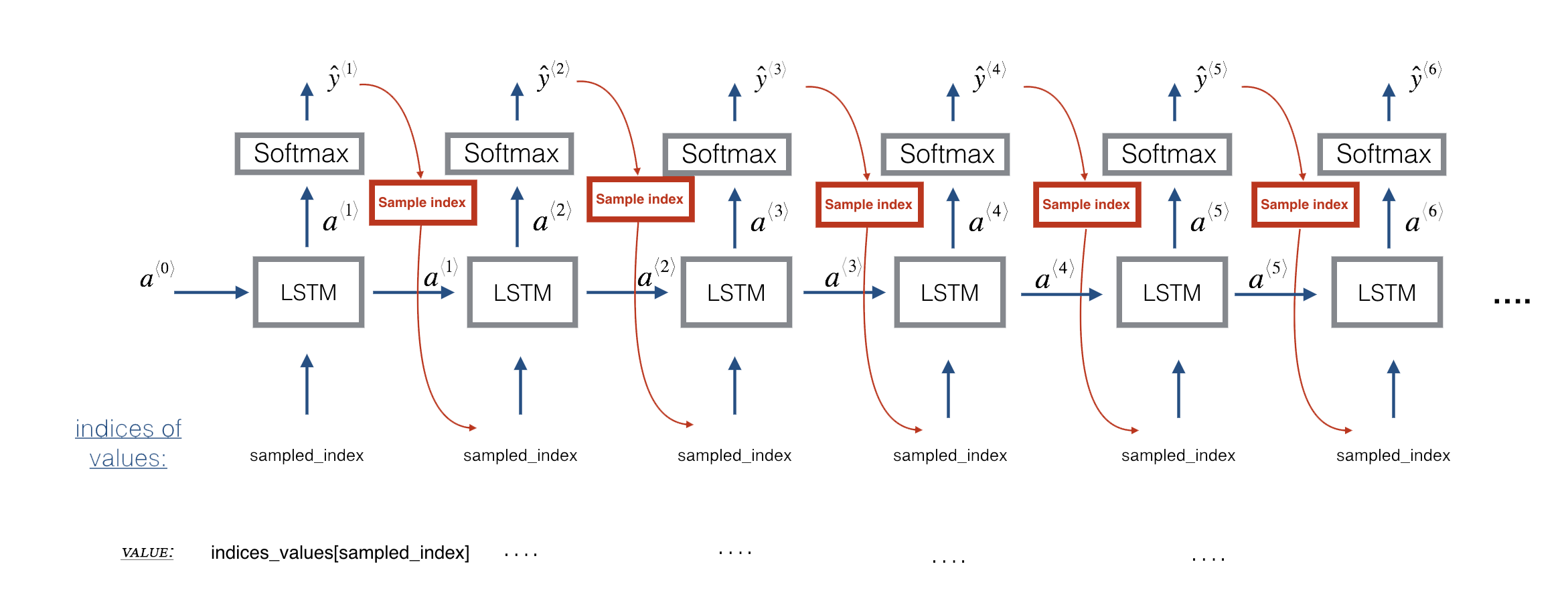
LSTM architecture
Training of the model uses random snippets of 30 values taken from a much longer piece of music:
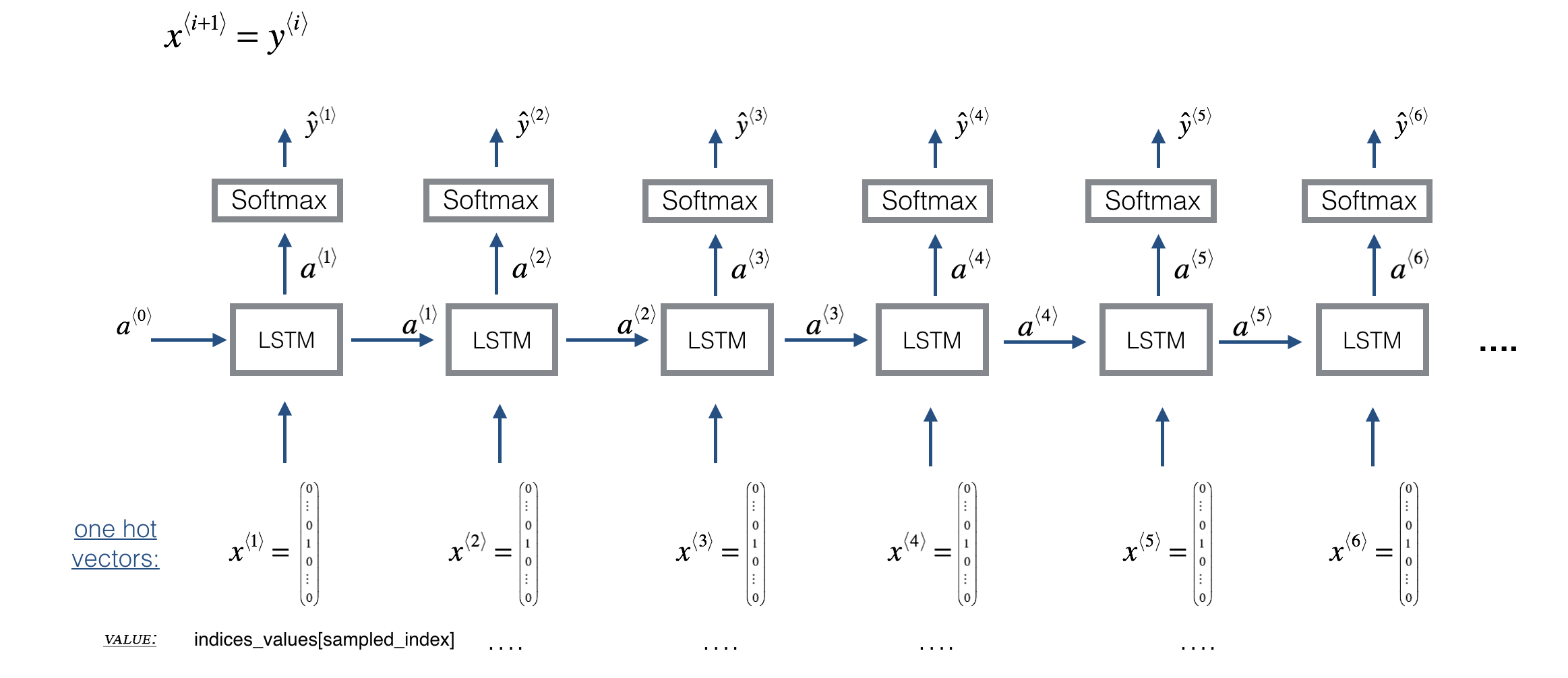
Prediction and sampling (i.e. generating new music) uses a slightly different architecture: